Today, I’m going to play the role of “armchair linguist” (which is fun and something everyone can do. Everyone can be an armchair linguist.) As much as I would love to pull some data and analyze some fun text, I’m deep in analyzing my dissertation data and should really focus my computing energy towards that.
However, I was thinking about sarcasm recently when writing about the phrase, “the internet is serious business.” This is a sarcastic remark (and an early meme) that pokes fun at people taking online discourse too seriously. In my little memo, I went back and forth between two constructions of sarcasm:
(1) Even if the internet is not ~serious business~,…
(2) Even if the internet is not sErIoUs bUsInEsS,…
Both are typographic markers of sarcasm that people frequently use in online communication. The first is an example of sparkle sarcasm, sometimes described as the “sarcasm tilde.” In Because Internet, McCulloch describes the tilde as having an exaggerated rise and fall that mimics the tonal features of sarcastic language. Even single-syllable words like “thaaaaaaaanks” and “soooooo” can be elongated for sarcastic effect. Many moments in South Park’s Sarcastaball episode show off this elongation.
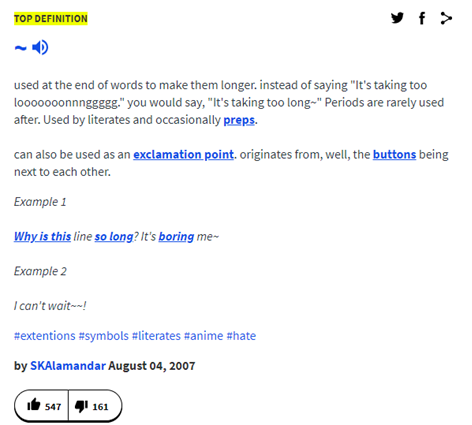
Source: Top definition for “~” on Urban Dictionary
The second is (now) an outgrowth of the popular “mocking spongebob” meme, which produced the now well-known sPoNgEbOb cAsE (fun fact: R has a sPoNgEbOb cAsE package, which you can check out here). I’ll call this spongebob sarcasm. The primary purpose of this case variation is to mock the tone of an idea or opinion—this draws from the mocking intent of the original meme. “Spongebob case” is obviously not the first use of alternating caps—like sparkle sarcasm, it was grouped with the use to tildes and asterisks constituting sparkly unicorn punctuation (~*~*iSn’T tHiS gReAt?!*~*~). But under the Mocking Spongebob meme, it’s taken on a life of its own, in the way that sparkle sarcasm is now distinct from ~*~*more ornate*~*~ uses of tildes and asterisks.

An early case of spongebob sarcasm. Source: (Know Your Meme)
So how is sparkle sarcasm different from spongebob sarcasm? In Because Internet, McCulloch notes a Buzzfeed reporter’s description of sparkle sarcasm: “somewhere between sarcasm and a sort of mild self-deprecatory embarrassment.” The use of sparkles suggests a type of “anti-serious” sarcasm that is “sing-songy.”
In contrast, spongebob sarcasm is direct and biting—a type of “insincere” sarcasm. If sparkle sarcasm is self-deprecatory, spongebob sarcasm is mockery. A core aspect of its early use included mockingly repeating what someone else has said (that norm carries to its current usage, even if mocking oneself):
(Above: my favorite example of spongebob sarcasm this morning)
Having both types of sarcasm gives online communicators a greater variety of “sarcasm” to choose from. And, because it is denoted with obvious markers (tildes and alternating lower and upper case), both sparkle and spongebob sarcasm are less likely to be taken at face-value; whereas tonally-conveyed sarcasm could produce a misunderstanding.
If we think of sarcasm as a language microcosm of satire, we could also think of sparkle sarcasm as Horatian (playful and light-heartedly humorous) and spongebob sarcasm as Juvenalian (i.e., ridicule). I bring this up to highlight that these variations of sarcasm and language are not inherently new. But, we have found new ways to communicate those ideas in daily computer-mediated language, which I think is super cool.
(PS: I went with spongebob sarcasm: tHe iNtErNeT iS nOt sErIoUs bUsInEsS!1!1!!one!!1!1!!!)