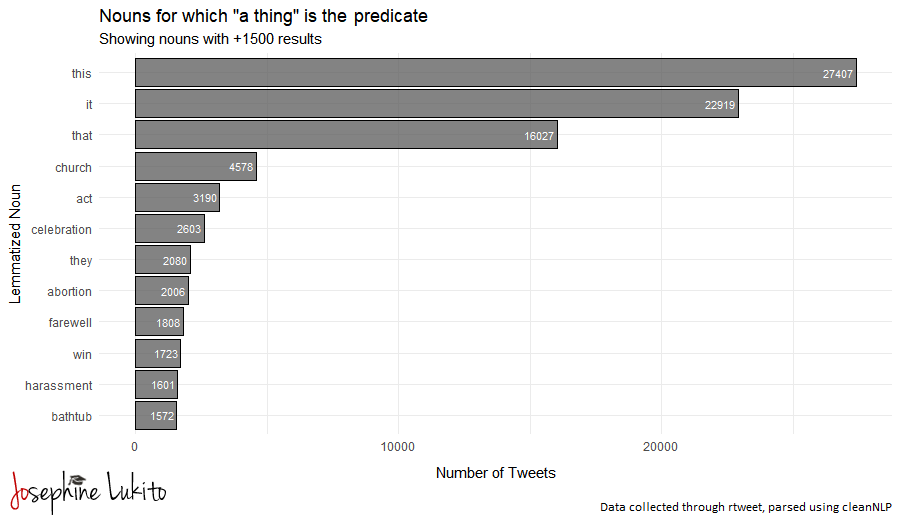
On December 12, 2019, Disney unveiled its streaming service, Disney+, to the world. It received significant attention, both good and back, from the press—which makes sense, because over 10 million people signed up in the first day.
Twitter was also abuzz with conversations about Disney+ (see this string-of-tweet “news story” about Twitter activity on the first day). Several pointed out that shows, including new ones like The Mandalorian and oldies like Darkwing Duck, were trending soon after Disney+ was launched.
But what would activity look like after the first day?
To answer this question, I used Mike Kearney’s rtweet package to look at tweets posted from 11/14/19 to 11/18/19 that had one of the following keywords: disneyplus, disney plus, disney+, and disney +.
Timeline
As with any long-term (> 1 day) popular topic (like elections), tweets about Disney+ had a natural seasonality. People tweet less after midnight and pick back up at 6 or 7 a.m. the next day. While activity was still pretty high on the 14th, people tweeted less and less about it over time (as would be expected). There was a little over a million tweets in the corpus (n = 1,107,413).
Topic Modeling
I also ran an LDA topic modeling, which highlights the variety of conversations on Twitter about Disney +.
Noticeably, The Mandalorian, Hannah Montana, the Simpsons (which is on Disney+ in its original 4:3 format), and Bad Girls Club were talked about frequently enough to be (mostly) stand-alone topics. The Mandalorian hashtag (#themandalorian) was also a popular keyword in the corpus.
But we also see a variety of other topics, including one about the Nickelodeon and Netflix deal (which many people viewed as a response to Disney+’s explosive popularity) and another comparing Disney+ to other streaming services (like Netflix, Hulu, and HBO). In fact, Netflix was the third most frequent term in the dataset (behind Disney and Disneyplus).
(Some of the topics were obviously noisier than others. Topics with the little red “n” are “noisier” than the others, meaning that a large number of tweets with a high beta in that topic were not related to the topic labels. Many tweets in the “Bad Girls Club” topic, for example, don’t actually have to do with that show.)
Sentiment-Laden Words
I did a quick sentiment analysis as well, using the tidytext package (specifically, the bing sentiment lexicon). This allowed me to look at frequently used, sentiment-laden terms.

As with any sentiment analysis that is based on a lexicon, there are obvious limitations. The bing dictionary, for example, includes “trump” as a positive word, but it would count any mention of Donald “Trump” as well.
We can see a similar phenomenon here with the word “chill”, which Bing treats as a negative word. If you recall from the topic modeling results, “Disney+ and Chill” was a topic in-it-of-itself. In addition to using the specific phrase “Disney+ & Chill” (which is a snowclone from “Netflix & Chill”), we see people trying to come up with their own variants, including “Disney+ and Thrust” and “Disney+ and Bust”.

For a quick and dirty analysis, this was a pretty fun corpus of tweets to go through! You can check out my code at my Github.